许多对大数据技术感兴趣的人都听说过 Google 在十年前发表的三项重要成果:Google File System(GFS),MapReduce 和 Bigtable[见表1]。Google 在这些成果中,介绍了其利用通用计算设备成功搭建分布式集群的方法。其中的诸多设计思想在后来被广泛借鉴。
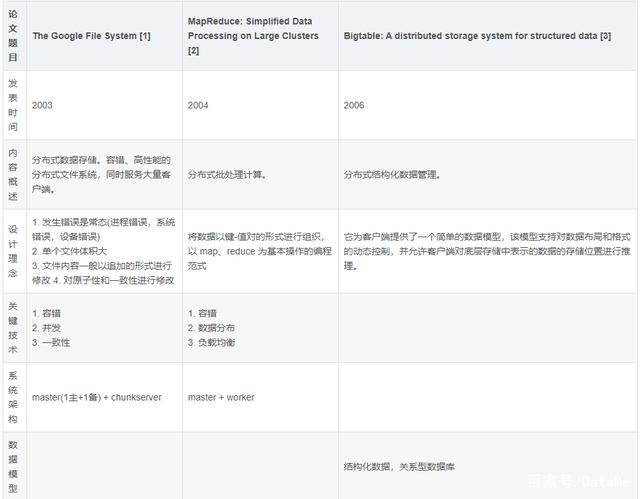
表1:相关论文汇总与比较
为什么要设计这些系统?
这些系统都有什么用处?
这些系统在实现上有哪些特点?对后来的系统设计有哪些启发意义?
本文通过提出一系列问题并尝试回答,介绍了现行大数据技术的核心设计理念和技术实现。
01分布式系统
为什么需要分布式系统呢?
在硬盘存储空间多年来不断提升的同时,硬盘的读取速度没有与时俱进。如果将大量数据存储于单个磁盘中,在分析时将需要耗费大量时间。
从 1990 年到 2010 年,主流硬盘空间从1GB 增长到 1TB,一千倍的提升,硬盘的读取速度从 4.4 MB/s 到 100 MB/s,仅有约20倍的提升[4]。以这种速度(100 MB/s)读完整个硬盘(1TB)的数据至少需要 2.5 个小时。
如何减少数据读写以及数据分析的时间呢?比较直接的方案是同时对多个硬盘中的数据并行读/写,即利用分布式系统存储和处理数据,提高I/O 带宽,但这一方案也会面临一些突出问题,例如:
更高的硬件故障频率。假如单个硬盘连续正常使用一个月的可靠性是 99.99%,一个月中 10000 个磁盘都不出错的概率只有 36.8%;“0.9999 的 10000 次方约等于 0.368”不同节点之间的数据组织和共享。一份数据要如何存放在不同磁盘上?不同节点上的数据如何更高效地通信、共享,从而避免网络I/O成为系统瓶颈?Google 的工程师意识到,如果想要利用分布式系统提高数据处理速度,同时又需要系统能稳定运转,必须想办法解决上述两个问题。Google Files System 就在这样的历史背景下诞生了。
02Google File System (GFS)
Google File System 解决了分布式系统上的文件存储问题。它提供了运行在廉价的商用硬件上的容错能力,并具备为大量客户端提供整体高性能服务的能力,目标是在分布式场景下解决文件系统关注的问题。如今被广泛使用的 Hadoop File System 几乎完全照搬了 GFS 的设计理念。
传统分布式文件系统要解决的主要问题:1. 性能 2. 可扩展性 3. 可靠性 4. 可用性
GFS 的设计者通过对业务工作的观察发现了一些通用设备集群的应用场景特点,针对这些特点重新设计实现了一个新的分布式文件系统。具体有哪些特点呢?本文会在下一节展开介绍。
GFS 的设计
结合 Google 所使用的分布式集群和程序应用场景,工程师在对 GFS 进行设计时重点考虑了以下问题:
1. 单点设备的问题会经常出现。大规模集群中同一时间单台计算机出现故障的概率不容小觑;
2. 系统主要用于存储大文件。文件系统存储数百万个大小在 100 MB 左右或以上的文件;
3. 对文件的常见操作为大规模的流式读取和小规模的随机访问;
4. 常见的文件修改为序列追加写入。一旦写入后,文件很少会再修改。任意位置的修改不需要被高效支持;
5. 高效支持对单个文件的并发追加操作。原子操作和小的同步开销是必要的;
6. 带宽吞吐比低延迟更重要。
系统架构
GFS 系统由一个 master 节点和多个 chunkserver 节点构成,系统同时被多个 client 访问,如下图所示:

GFS 架构示意图[1]
图中每一个工作节点,一般为一台 Linux 系统的商用计算设备上运行的用户态服务进程。文件会被拆分成固定大小的块(chunk),每一个块用固定的 64 位区块句柄唯一标识,块标识的工作由 master 节点完成。系统的运转过程中包含多种角色,各有分工,互相合作:
* master 节点存储文件系统的所有元数据信息;
* chunkserver 负责存储数据。master 和 chunksever 之间通过定时发送的心跳信息交流;
* 客户端与主服务器进行元数据交互,获取要访问数据的块信息,数据块内容的传输则由 chunkserver 完成。
解决了分布式文件存储问题之后,自然就要关注分布式场景下的计算问题了,Map Reduce 编程范式和计算系统应运而生。
03MapReduce
MapReduce 有什么用?
MapReduce 编程范式的提出是为了简化大型集群上的数据处理。以这种形式编写的程序可以在大型集群上并行地调度、运行,无需程序编写者考虑分布式系统的资源、通信等细节问题。MapReduce 的主要贡献是提供一个一个简单而强大的编程接口,它支持大规模计算的自动并行化和分布。结合了该接口的实现,可以在商用 PC 集群上实现高性能数据处理。MapReduce 的相关思想,应用在了Hive、Spark等计算引擎的系统设计。
MapReduce 设计
MapReduce 的设计思想可以结合下图解释:
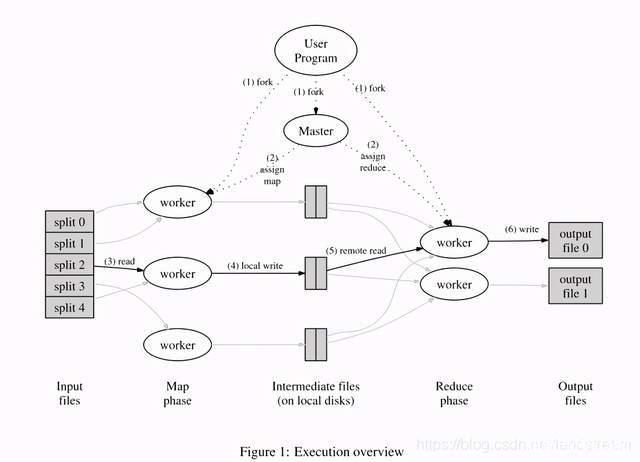
MapReduce 模型示意图[2]
Map Reduce 面临的挑战是计算过程中的容错,包括:
1. 应对 worker 故障:定期检查发现 worker 错误;重新执行故障 worker 对应的任务
2. 应对 master 故障:定期备份,存储 checkpoint 数据
3. 用户代码逻辑异常应对方法:依赖于 map/reduce 任务状态提交的原子性,确保最终输出结果是确定的。
如何在分布式场景下,构建大规模结构化数据管理能力?这是工程师面临的另一个问题。Google 工程师为了解决这个问题,设计实现了 Big Table 系统。
04Bigtable
Bigtable 系统的设计目标是什么呢?
主要是为了在数千台设备的商用设备集群上实现对超大规模结构化数据的存储管理。Bigtable 支撑了 Google 的网页内容索引,Google Earth 以及 Google Finance 等多个重要应用,对 Hive 的产生具有重要的启发意义。
数据模型
Bigtable 的数据将以 SSTable 的形式持久化存储,SSTable 相关知识请另外自行查阅。其索引结构如图所示:
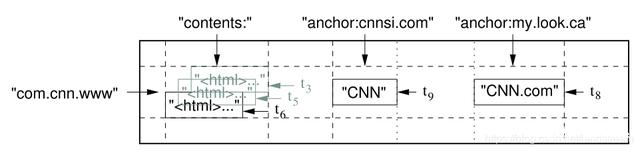
Bigtable 的查询原理是根据 row key, column key, timestamp 等字段,得到对应的 value。相关字段的属性信息如下:
* row key:大小一般在 10-100 bytes,最多 64KB。对一个 row key 的读写操作是原子的;
* column key: 由 column family + column key 组成;
* timestamp:64位整数,以微秒或其他形式存在,用于实现数据的版本管理。在产生时间戳时要避免碰撞。
设计思想
Bigtable 的主要设计思想如下:
1. 可扩展性
2. 高性能
3. 向外提供特别的接口,不支持完全的关系数据模型;
4. 动态支持数据格式和 schema 变化,客户端可以对数据的存放位置进行推断;
5. 索引由 row 和 column 等字符串联合构成;
6. 将数据内容作为不可解释的字符串对待;
05
—
总结
在以大量 x86 服务器搭建的分布式集群上设计实现系统时,需要考虑的关键问题可以总结如下:
1. 数据分布(Location):数据在集群中的分布。为了提高 I/O 效率,避免主机之间的网络通信成为全局瓶颈,需要对数据在整个集群的分布做出合理安排,将经常被一同访问的数据尽量安置在一起;
2. 容错:考虑在大规模集群中,单点故障可能导致的故障问题;
3. 一致性:分布式场景下需要将数据做分开备份以避免单点故障造成数据永久丢失,这也使得机器间数据状态一致性更难控制;
4. 负载均衡:避免单个机器承担过多工作,应该尽可能发挥每台机器的性能,提升大型工作的执行效率。
个人评价
用通用服务器(commodity server)集群搭建的系统相比大型机具有更强的可扩展性和容错能力,同时具有一定的设备价格优势。Google 在这方面做了相关工作,并用自己的成功有力地证明了该方案的可行性。在今天,互联网服务提供商大多也采用了通过搭建通用计算机集群支撑自身服务的飞速发展,除了财大气粗追求稳定的银行业之外,几乎没有人愿意再去选择购买昂贵的大型机了。
思考与质疑
CAP 是分布式系统逃不过的问题,响应时间和一致性是存在矛盾的。commodity server 集群搭建的系统存在的突出问题是一致性问题,同时,集群中不同节点之间的通信也可能成为瓶颈,而且相比大型机来说,总的能耗更高。
参考文献
[1] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. 2003. The Google file system. In Proceedings of the nineteenth ACM symposium on Operating systems principles (SOSP \’03). ACM, New York, NY, USA, 29-43. DOI: https://doi.org/10.1145/945445.945450
[2] Jeffrey Dean and Sanjay Ghemawat. 2004. MapReduce: simplified data processing on large clusters. In Proceedings of the 6th conference on Symposium on Operating Systems Design & Implementation – Volume 6 (OSDI\’04), Vol. 6. USENIX Association, Berkeley, CA, USA, 10-10.
[3] Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber. 2006. Bigtable: a distributed storage system for structured data. In Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation – Volume 7 (OSDI \’06), Vol. 7. USENIX Association, Berkeley, CA, USA, 15-15.
[4] Hadoop 权威指南
