在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统称为分布式文件系统。
HDFS
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口。
HDFS是根据谷歌的论文:《The Google File System》进行设计的
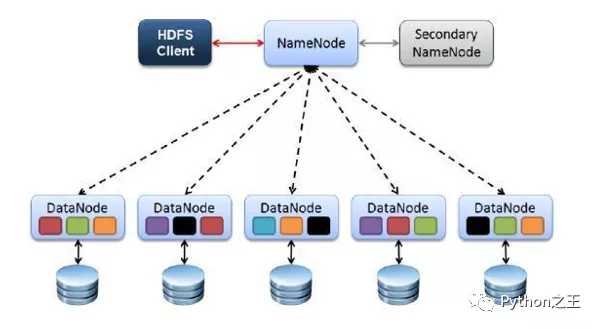
HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode。
Client
Client是客户端。HDFS Client文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
NameNode
NameNode就是 master,它是一个主管、管理者。管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件的block切片信息)。
NameNode管理 Block 副本策略:默认 3 个副本,处理客户端读写请求。
DataNode
DataNode就是Slave。NameNode下达命令,DataNode 执行实际的操作。
DataNode存储实际的数据块,执行数据块的读/写操作。定时向namenode汇报block信息。
Secondary NameNode
SecondaryNameNode不是NameNode的备份。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
辅助 NameNode,分担其工作量。在紧急情况下,可辅助恢复 NameNode。
副本机制
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
在hadoop2 当中, 文件的 block 块大小默认是 「128M」(134217728字节)。
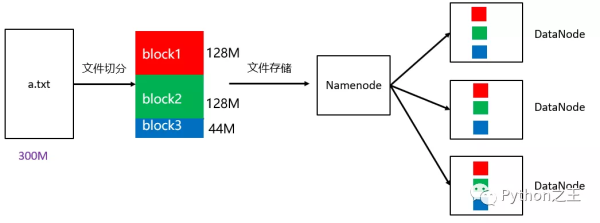
如上图所示,一个大小为300M的a.txt上传到HDFS中,需要进行128M的切分,不足128M分为到另一block中。
HDFS基本命令
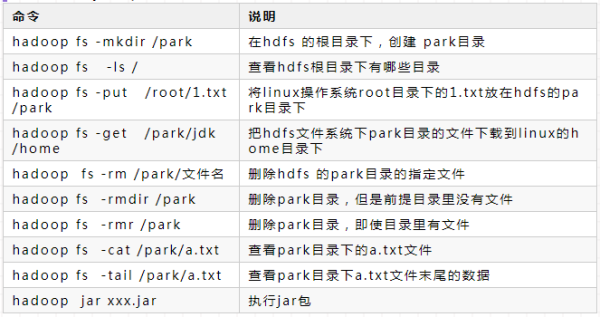
HDFS 简单使用
根据部署的服务,我们的 HDFS 根目录是 hdfs://192.168.147.128:9820,下面我们尝试在根目录下面创建子目录 user,如下命令所示:
[hadoop@node01~]$hadoopfs-mkdir/user
然后在Hadoop页面打开HDFS。
此时的user文件夹将会看见。
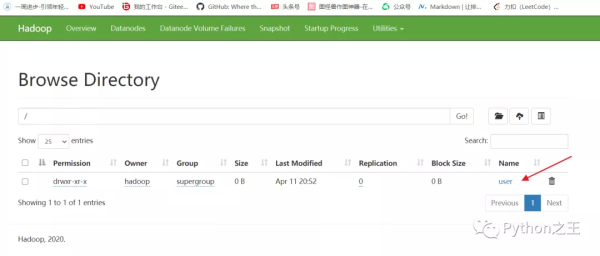
下面将一个大小为300M的文件上传到HDFS的user文件夹中

然后在Hadoop页面看见刚刚上传的文件。
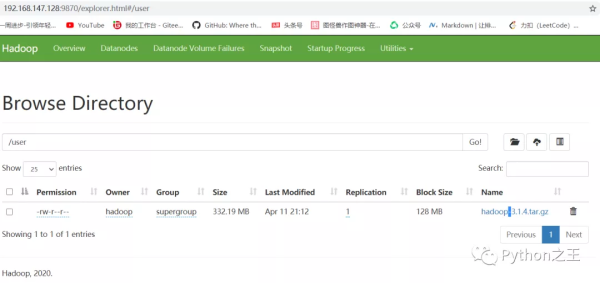
此时被分开了三个block。